

DatabaseTiger Data (Timescale)Inglese (alto segnale quando c’è poco volume locale)
Database


Learn why PostgreSQL reads 16x more data than your queries need, and how a hybrid row-columnar storage layout eliminates the bottleneck without changing your SQL.
Participate in the PostgreSQL 19 beta program using Kubernetes and our CloudNativePG operator
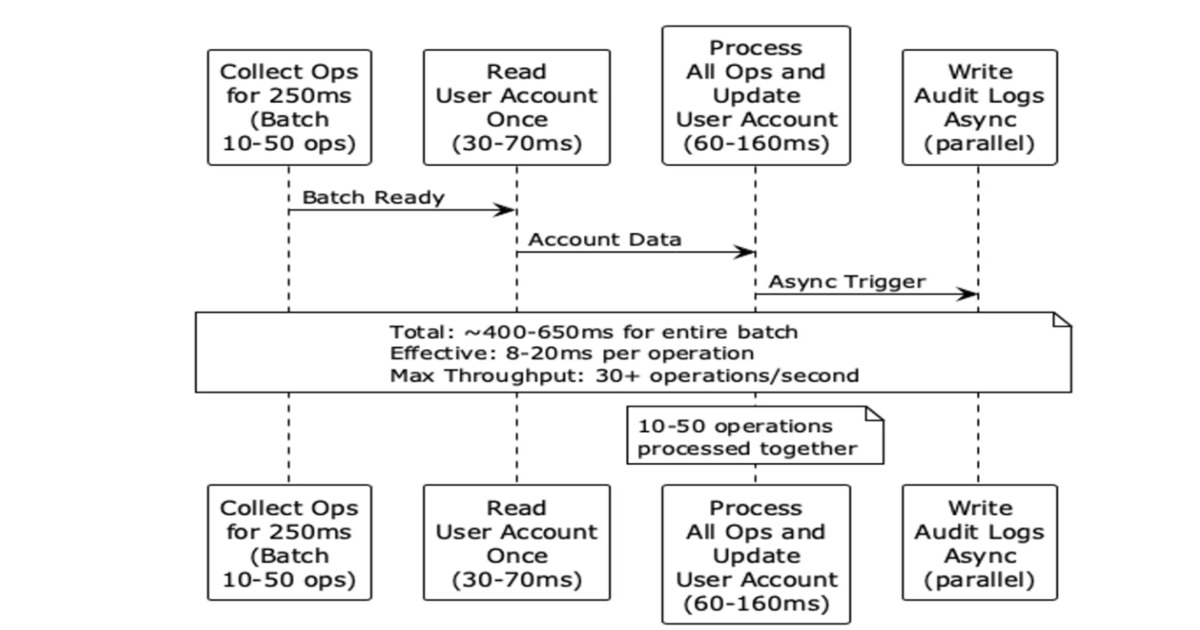
Uber introduced a high-throughput financial ledger processing system designed to handle hot account write contention at scale. Using 250ms batching, Redis coordination, and optimistic atomic updates, the system supports 30+ updates per…
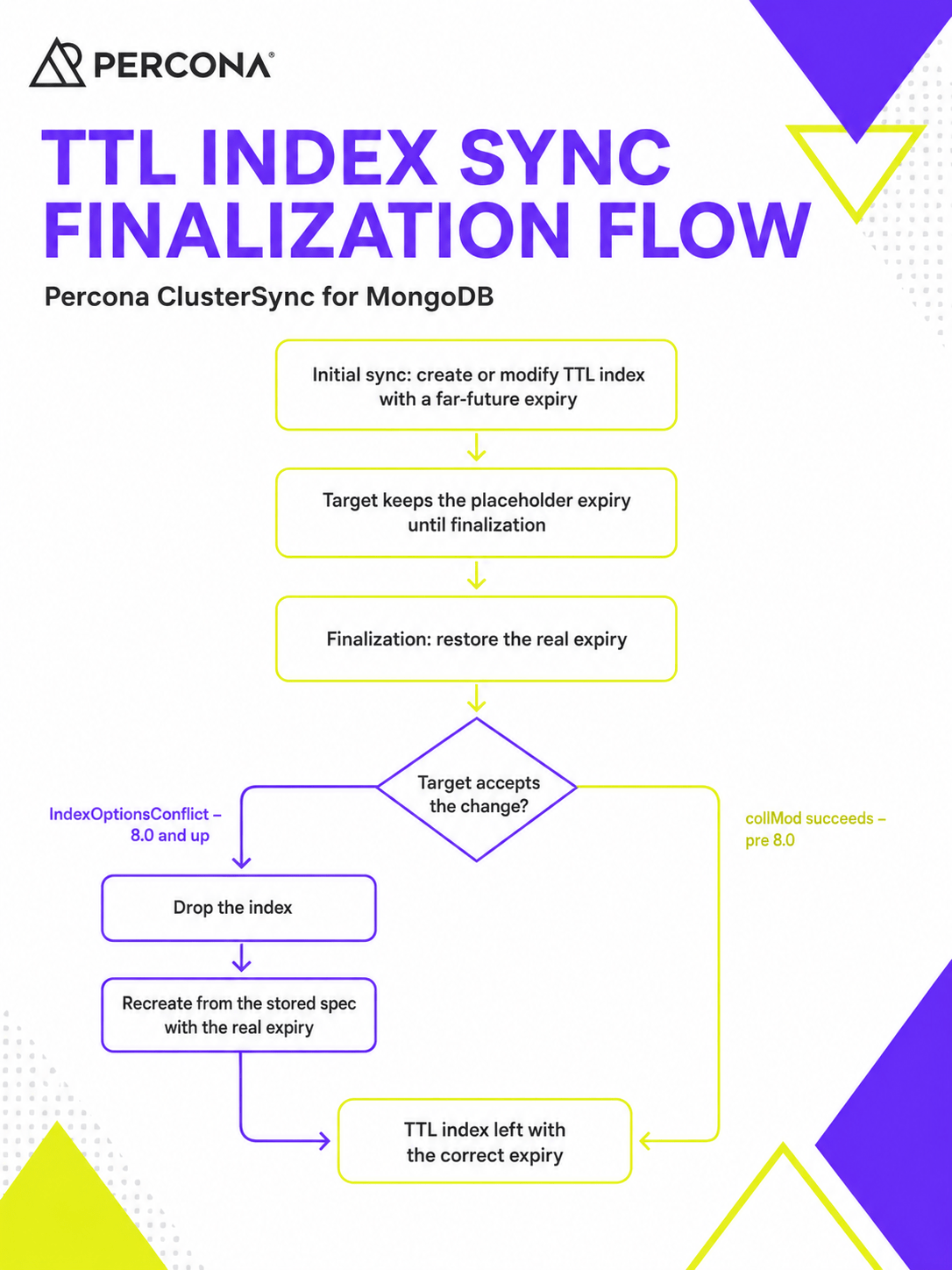
Percona ClusterSync for MongoDB (PCSM) replicates data between MongoDB clusters to keep migrations with near-zero downtime. Prior to version 0.9.0 it required the source and target to run the same major version, which ruled out the…